HOME > ニュース > AV&ホームシアターニュース
NHK、40年分の放送局データを用いた大規模言語モデルを開発。大量の情報収集・翻訳・校正などを支援
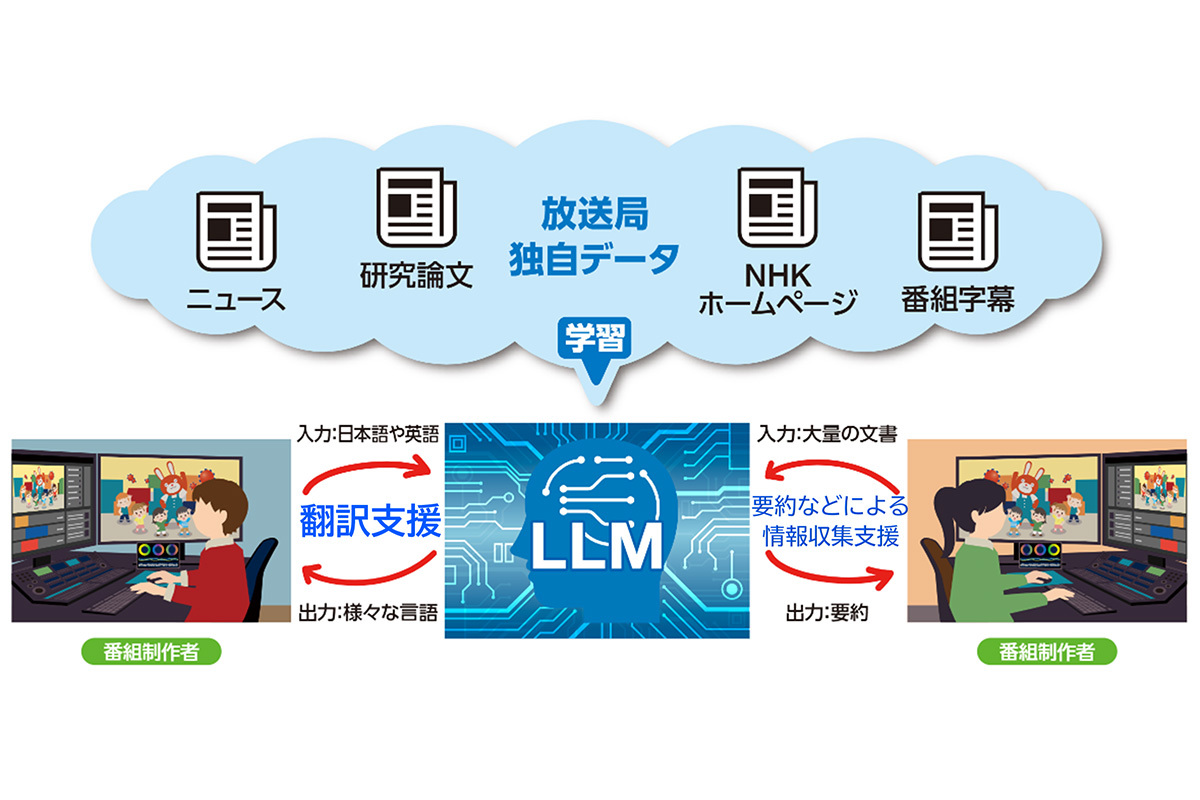
NHK放送技術研究所は、NHKが放送したニュースなどの放送局データを用いた大規模言語モデル(LLM)を、2026年までの実用化を目指して開発を進めていくと発表した。
大規模言語モデル(以下、LLM)とは、大量のテキストデータを学習することで、あるテキストを入力すると、それに続くテキストを予測して出力する、自然言語処理に特化した生成AIの一種。とくに放送局業務おいては、翻訳、要約、文章校正、プログラム作成など、幅広い応用が可能となる。一方、利用上の課題としてLLMが事実と異なる回答をしてしまう点が指摘されていた。
そこでNHK放送技術研究所は、既存のLLMをベースに、過去にNHKが放送した約40年分のニュース原稿やニュース記事、番組字幕などの放送局データ(約2000万文)を追加学習させたLLMを構築。これによってニュースの内容への理解が深まり、事実と異なる誤った回答をしにくくなったほか、頻繁に使用される用語や表現に対する理解力が向上したという。
外部機関が実施するニュース報道に関する検定試験を用いた評価実験では、LLMに放送局データを学習させることが、ニュース報道に関する質問において、回答の正確性の向上にどの程度効果的かを検証したところ、報道された事実に関して、誤った回答をする割合が学習前と比較して約1割減少したとのこと。
今回構築したLLMはニュースの時事的な知識を獲得していることも確認できたが、番組制作支援のツールとして活用するにはさらに改良が必要という。大量の文書の要約など情報収集の支援、翻訳、文章校正などの業務支援を想定して、2026年までの実用化を目指して研究開発を進めいくとしている。
この技術は5月29日(木)から6月1日(日)まで開催される「技研公開2025」で展示される。今後はLLMの回答精度向上に加え、テキストだけでなく映像や音声など多様な情報を扱うマルチモーダル化に取り組み、安全性と機能性を兼ね備えたLLMの開発を目指すとのこと。
この記事をシェアする