<山本敦のAV進化論 第147回>
ソニーのコミュニケーションロボット『Xperia Hello!』は「スマートスピーカーの先を目指した」
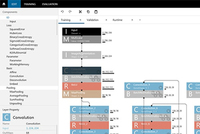
Hello!には、今回ソニーが内製した音声・画像認識のセンサーがXperiaのスマートプロダクトとして初めて搭載されている。センサーから入力された情報をもとに、クラウドやローカルのAIエンジンをハイブリッドに活用しながらユーザーに有用な情報を提供する。独自の「ソニーエージェントテクノロジー」をベースに開発されたものがHello!の頭脳だ。
同じ技術は、ソニーモバイルのウェアラブルデバイス「SmartBand Talk/SWR30」や「Xperia Ear」「Xperia Touch」、Androidアプリの『めざましマネージャー』などのサービス・製品のベースアーキテクチャにもなっている。
Hello!は音声と顔認識を使ってスタンバイ状態から起動し、音声コマンドによるリクエストを待機する状態に切り替わる。使用環境の周囲に様々なノイズがあっても正確に音声コマンドが聞き取れるよう、音響エコーキャンセラーや雑音抑圧などを組み込みソフトウェアで処理を行う。そして発話意図解析、語彙認識をクラウド側のソフトウェア処理を組み合わせながら行って、一連の音声認識処理を素速く行う。
顔画像認識については登録した家族を素速く、安全に識別できるように基本的にデバイス内部で処理を行っている。かつてソニーの液晶テレビ“ブラビア”が搭載していた、カメラで顔認識とユーザーの動き検知を行って自動で消画する「インテリジェント人感センサー」から得られたノウハウの一部もここに活きているようだ。
入力されたコマンドの意図を理解して対話を組み立てる方法は、ふたつのパターンを採用しているという。ひとつは頻出するであろうコマンドをあらかじめ想定・組み込み、入力された時にパターンマッチをさせて理解するルールベースでの発話生成。もうひとつが機械学習の履歴を活かすパターンだ。コマンドをテキストで認識した後、Hello!は応答シナリオのデータベースを参照しながら、最適な答えをユーザーに返してくる。
Hello!は多彩なユーザーインターフェースを持つロボットだ。ひとつは生声と音声合成による「ハイブリッド音声発話」。さらに滑らかで静かに動く可動部が「腰と頭」にある。そして先に触れたお腹のディスプレイだ。ユーザーのコマンドに対して、素速く正確に、そしてかわいらしく自然に応答するHello!は、何気なく動いているように見えるかもしれないが、バックグラウンドでの技術の合わせこみは非常に大変だったと城井氏が振り返る。
「話す・動く・見せるという3つの表現がタイミング良く同期しないと、動きがちぐはぐになってしまい、答えがわかりにくくなってしまいます。3つのUIを同期・連携させようとすると、ひとつのUIを完成させるよりも難しさがかけ算式に膨らんできました。エンジニアたちのハードワークの賜物だと思っています」(城井氏)

話す・動く・見せるという動作の融合が重要であり難しいところでもあると城井氏
やりとりを音声だけに頼ってしまうと「時間を食う」ことがひとつのデメリットにもなると城井氏が指摘する。音声による読み上げは最後まで聞かないと、結果がYesなのかNoなのかもわからない場合もあるが、ディスプレイにそれを表示してあげれば目で見てすぐにわかるし、記憶に残りやすい場合もある。本体のジェスチャーを使って答えを目に見える形にしてあげることで、応答の結果もかけ算式に数倍強く、深くユーザーの記憶に刻み込まれる。
人に近いふるまいを交えることで、エレクトロニクス機器に対する親しみが沸いてくるし、コミュニケーションに和みの効果が生まれる。スマートスピーカーやスマホのAIアシスタントに対して「音声で会話することの抵抗感」を指摘する声もあるが、Hello!のようにキャラクターや人格を帯びている機器に向かい合うと、自然と声をかけてみたくなる。
ハイテク好きな人々でなくてもHello!に関心が沸いてくるだろうし、実際に高齢者介護の施設でヒト型ロボットが活躍している事例もある。「インターフェースについてはまだ試行錯誤している部分もありますが、Xperia Hello!は“お話しすることが苦にならないロボット”にしたいと考えています」と語る倉田氏の言葉からも、Hello!のようなコミュニケーションロボットが求められている役割の在り方が見えてくる。

“頭”の部分や目にあたるLEDを動かすことで、表情を作り出している
■“空気を読む”まで育てたい
Hello!はユーザーからアクションを起こさなくても、時どき自発的に話しかけてくることもある。これはどんな仕組みやルールで動いているのだろうか。
「人感センサーでユーザーが近づいてきたことを検知して、“おはようございます”などのあいさつをしてきます。ユーザーへのメッセージが溜まっていると、顔を認識した時にそれぞれの家族宛のメッセージを自動で読み上げてくれます。交通情報のアップデートがあった場合なども、こちらから聞かなくても教えてくれます。自律型ロボットのAIが自ら話しかけてくるケースについては、そこに何かしらの必然性がないと使い心地がかえって良くないと考えているので、今のところ限定的な範囲にとどめています。発売後にもフィードバックを得ながら、ユーザーが心地よく感じられる、あるいは役に立つケースをリサーチしながら加えていきたいと考えています」(城井氏)。
最終的にはHello!がユーザーとの関係性をリアルタイムに理解して、“空気を読める”ようになることが理想だと、城井氏と倉田氏は口を揃える。「Hello!が最終的に家族の一員になるためには、ユーザーから『これって何だったっけ?』『あれ取って』といった感じに、曖昧な指示を含むコマンドを伝えられても、文脈で理解しながら適切な応答を返せることが究極の進化形だと思っています。そこまで駆け上がるにはまだ高い壁もあります」(城井氏)。
この記事をシェアする